A Semi-Technical Primer on LLMs: Pt. 4 Where We Stand Today and the Path Beyond
Progress levers, blockers, frontiers, and questions that are shaping the path forward.

![A Semi-Technical Primer on LLMs - Pt. 4.gif [optimize output image]](https://substackcdn.com/image/fetch/$s_!uUn4!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F25fc6fff-cb53-4aba-882a-436b86dd9f2d_1152x648.gif "A Semi-Technical Primer on LLMs - Pt. 4.gif [optimize output image]")
In Parts 1-3 we covered how LLMs work and the upgrades that made them useful. If you remember, back in the way beginning, the goal of all this was to come up with better insights.
Leveraging our technical understanding, we’ll do this by first thinking about what progress means and how it’s generally developed. Then, we’ll use that foundation to better understand where issues lie today and how research at the frontier is aiming to mitigate them. Lastly, we’ll finish off with how to frame the future.
We’ll cover this through the following sections:
Defining Progress
Levers for Improvement
Today’s Friction Points
Current Research Frontiers
The Great Debate
Let’s dive in!
1. Defining Progress
In Part 2, we covered evals and benchmarks, but at its core, progress is about simply providing economically feasible value in the real world.
To capture this, we can think of a simple, conceptual yardstick: value per dollar-second. What matters is that the model is providing value and is quick and cheap enough to to operate in real-world scenarios, not just demo land.
There are different ways to think about concretely defining and measuring this, but (for our purposes) that’s not important — we’ll leave that for eval creators. At the end of the day, “progress” is fairly intuitive. Do more for less. We just need to agree that increased value and/or decreased latency/cost will increase real-world transformation and that’s what matters most.
Intuitively, the model’s are getting better, but we need a structure to think about why they are getting better, especially if we want to think about how that may persist into the future.
2. Levers for Improving Models
When it comes to increasing value per dollar-second, every capability improvement comes from pulling one or more of a set of levers. These levers fall into two categories:
Where Change Happens: The part of the model’s lifecycle we modify.
Mechanisms That Enable Change: The resources we use to make those modifications possible.
For #1, improvement to a large language model (LLM) happens somewhere along its life cycle: architecture, training, inference.

We can change how an architecture is organized — it’s structure — or how large it is. In training, we can influence pre- or post-training. And in inference, we can impact serving or orchestration.
Underlying the three stages, there are just three fundamental types of mechanisms that improve performance: algorithms, data, and compute.
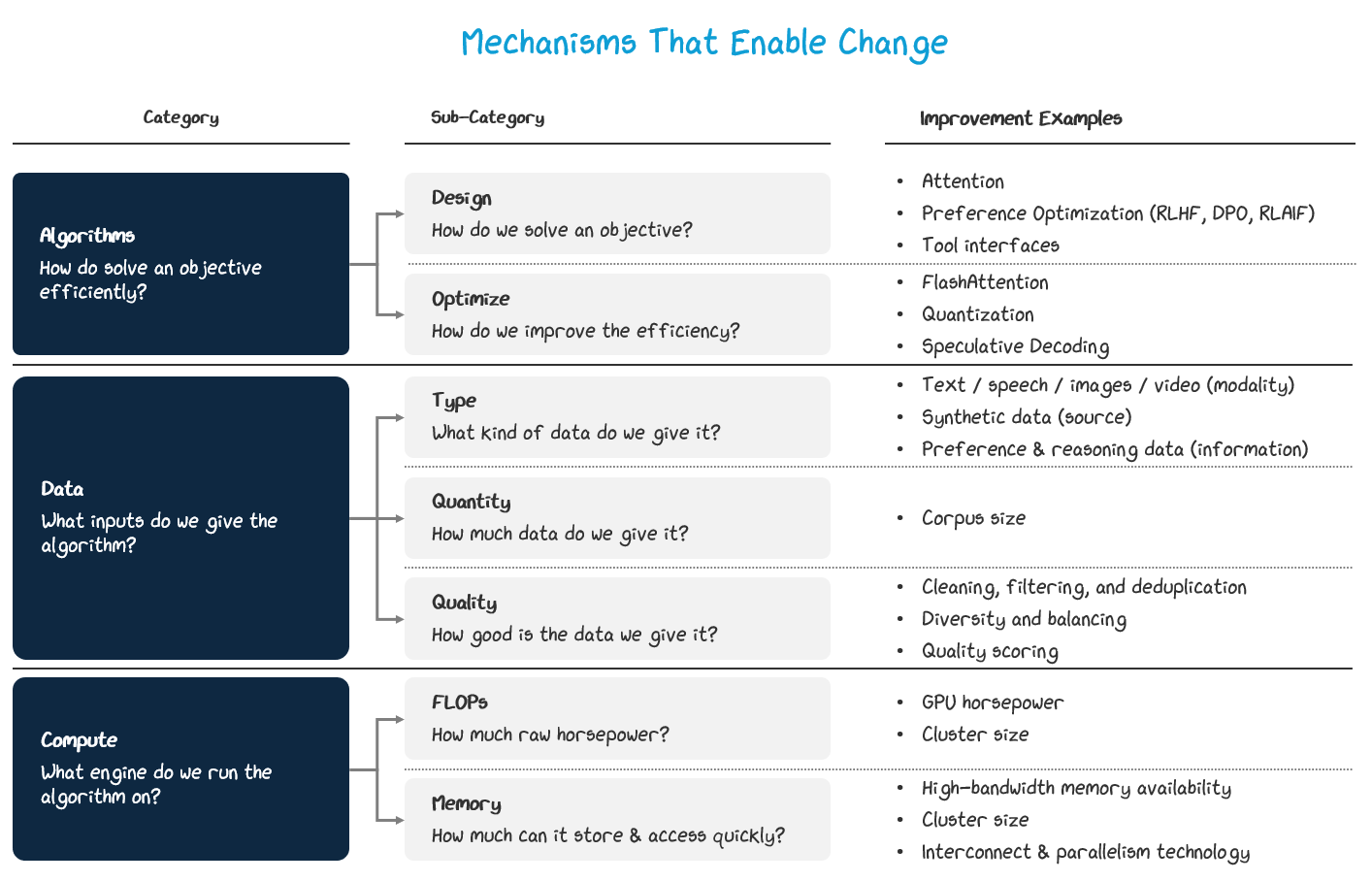
Algorithmic improvements can shape architecture, training, and inference. Compute improvements will shape training and inference mechanics, with implications on architecture. And data improvements will influence training mechanics, with downstream influence on the architecture.
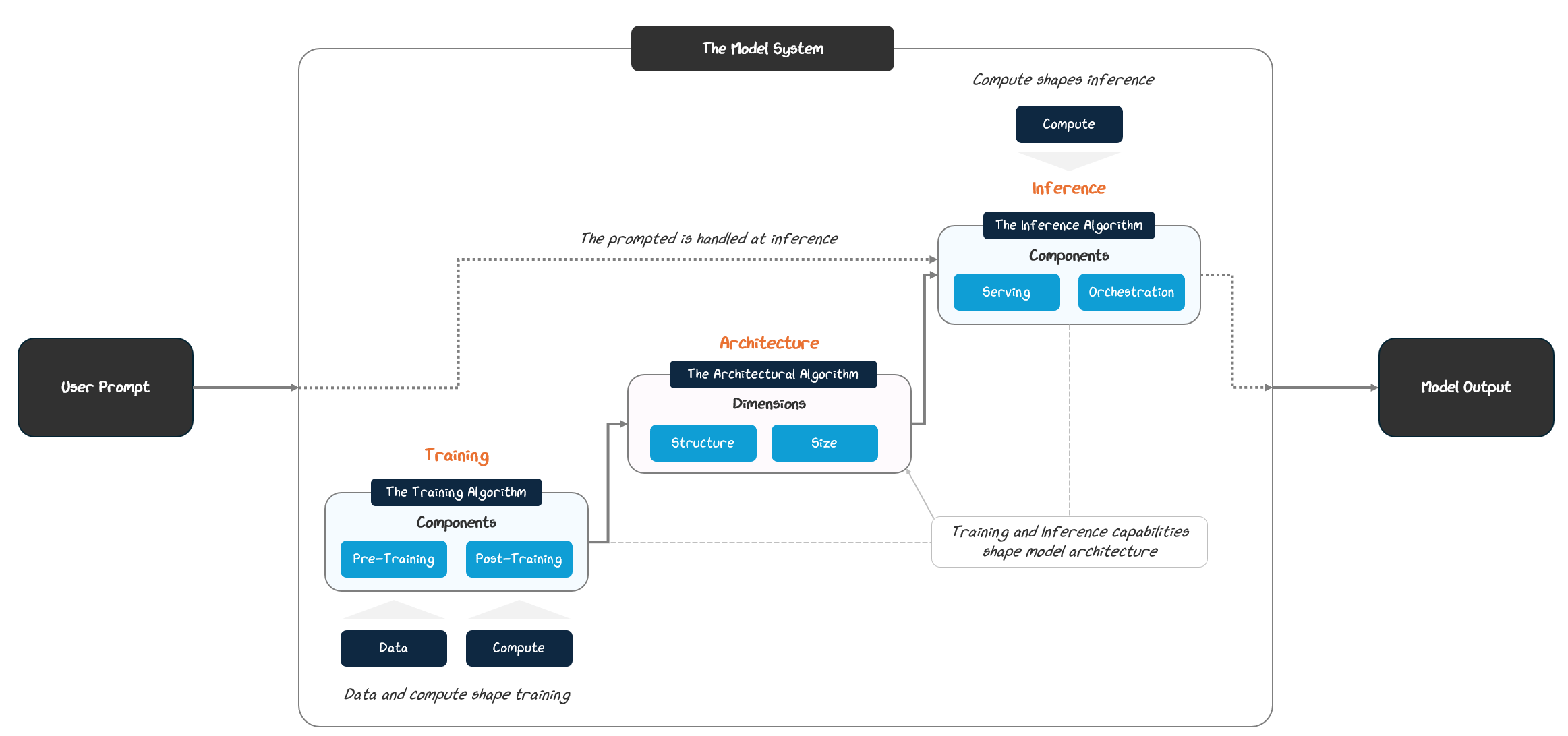
It’s this interconnected system with three areas for improvement and three mechanisms to create that change. Understanding this dynamic: capability improvement → improvement areas → underlying mechanisms provides us with a strong foundation to structure, categorize, and make sense of improvements.
3. Friction points
Models have been improving, but we’ve been pulling the same levers for a bit now. After the transformer architecture was made, we leveraged data and compute at scale to employ massive pre-training phases on huge architectures (reaching billions of parameters). After realizing diminishing returns to scale, in 2022, we then turned our focus to post-training to improve usability.
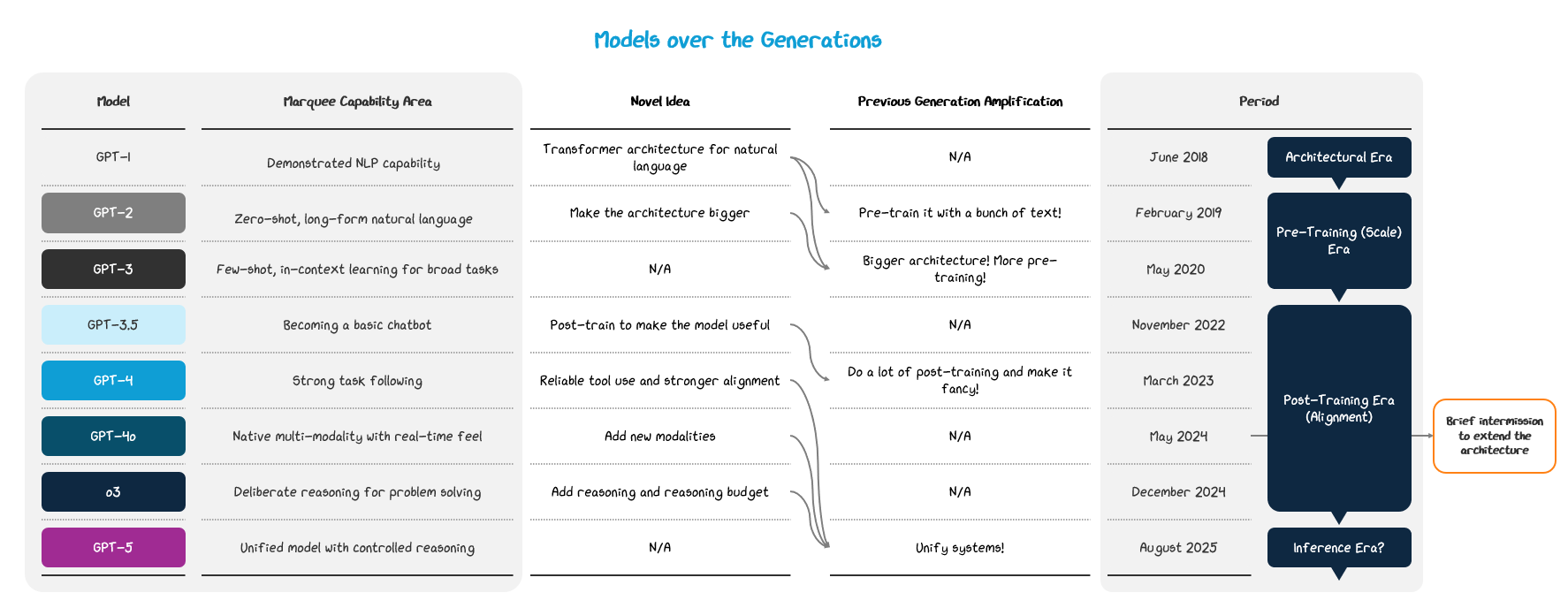
These levers still work, but the returns are smaller and we don’t yet have perfect models. The industry is currently bottlenecked by a few key critical areas gatekeeping the next level of model capability:
Truthfulness & Calibration: While much reduced, models still suffer from hallucinations, overconfidence, and weak grounding.
Reasoning Stability: Models remain prone to brittle multi-step chains in math, code, and long documents. Small slips or step drift can derail outputs, often showing up as schema violations or broken function calls.
Alignment & Incentives: Sycophancy, over-refusal, and benchmark transfer gaps persist. Models can perform well on evals yet miss desired behaviors under domain shift or adversarial prompting.
Unit economics: The cost per correct, grounded answer and latency for complex queries remain too high, limiting usefulness in the real world.
This combination is preventing the next stage of growth potential as it constrains the trust and confidence we can have on these models, especially for high-value and complex tasks — the exact kind we want them doing.
As a case in point, these challenges make activities like tool-calling to book an optimal flight prohibitively challenging. Frontier models still aren’t even able to complete this task at higher than 60% accuracy.
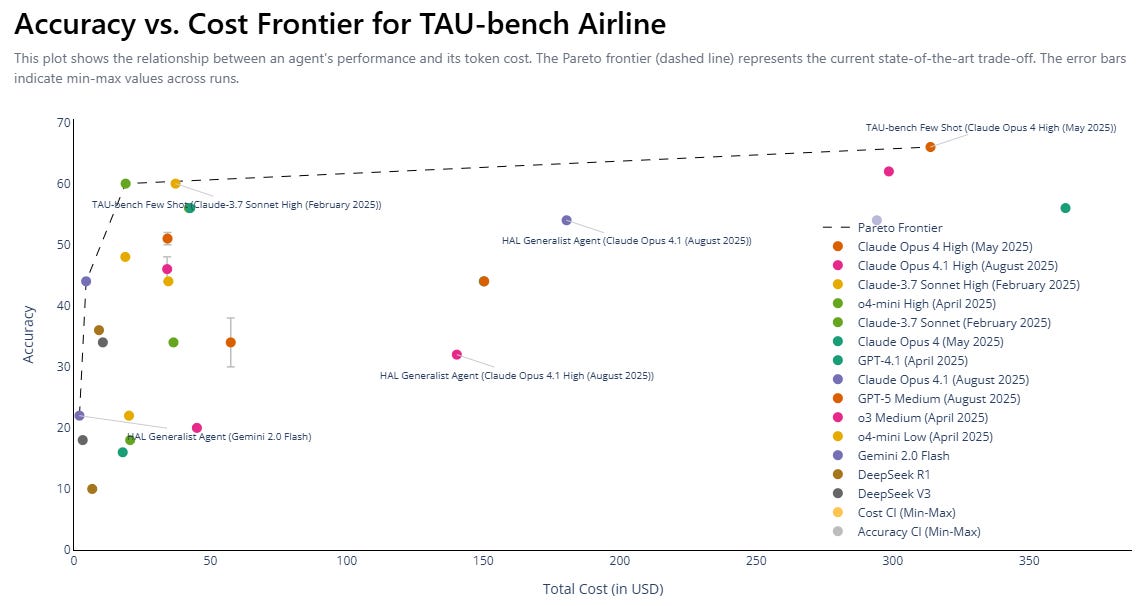
Even GPT-5 (medium) scored just ~50%! We still haven’t broken through yet.
But, there’s still hope! The best and brightest in the industry are working hard on these problems. The next unlock could be right around the corner.
In the next section, we’ll cover some of the most focused on research frontiers, through the lens of our levers.
4. Research Frontiers
To break through today's friction points, researchers are pursuing a wide range of innovations. These frontiers represent fundamental shifts in how we build, teach, and use AI, not just incremental improvements.
We can’t cover everything, so let's explore some of the most interesting paths, broken down by where the change happens.
4.1 Architecture: Rethinking the Blueprint
The engine behind the current generative AI boom is the Transformer. Its self-attention mechanism was a revolutionary breakthrough, allowing models to understand the relationships between words across vast stretches of text. However, this power comes at a cost. The Transformer’s core design is computationally intensive. Costs scale quadratically with the length of the input, creating a practical ceiling on context length and driving up the price of every query.
To move past these inherent limits, researchers are designing entirely new blueprints that tackle these weaknesses head-on. We'll explore three of the most promising paths, each introducing a different foundational capability into the model's design: radically efficient sequence processors like State-Space Models, memory-based architectures that have an external, persistent memory, and Neuro-Symbolic Hybrids that integrate a formal engine for logic.
4.1.1 State-Space Models (SSMs)
Area: Architecture; Mechanism: Algorithm; Goals: Reasoning Stability, Unit Economics; Horizon: Near term (1-3 years)
One of the most promising architectural frontiers is the State-Space Model (SSM). SSM is a fundamental algorithmic redesign of how a model processes sequences. Instead of the Transformer's all-at-once approach, an SSM processes information linearly, one piece after another, carrying a compressed "state" of what it has seen so far. This linear change directly breaks the quadratic scaling bottleneck that makes Transformers so computationally intensive.
At each step, the model looks at just two things:
the new piece of information (a word or token)
its current state, a compact summary of everything important it has seen so far.
The breakthrough of modern SSMs lies in making this process selective. The model learns to use data-dependent "gates" that decide how much of the old memory to keep and how much of the new information to add. For common filler words, the gate stays mostly shut, preventing the memory from getting cluttered. This selective, step-by-step update is the key, as the model's workload stays small and grows at a constant rate as the sequence gets longer.
The Transformer on the other hand does not compress the history at all. It considers the entire history through its attention mechanism. For long contexts, this can be overwhelming. In a 100,000 word context, at the last word, the space state model just needs to process (a) the 100,000th word and (b) its compact state passed down from word 99,999. The cost grows in a straight line, unlike the exponential curve from the Transformer / attention which needs to compare all 100,000 tokens against each other.
As a result, SSMs offer a potentially powerful solution to two critical friction points. They dramatically improve Unit Economics by lowering cost and latency, and they enable vastly larger context windows, enhancing Reasoning Stability over long documents or conversations.
Currently, this comes with a tradeoff in capability, but researchers are trying to see if they can preserve the efficiency and scalability while boosting capability through architectural hybrids, better state management, and scaling / optimization (i.e., bigger architectures, more training data / compute).

If you’re interested in learning more about how it works, check out A Visual Guide to Mamba and State Space Models.
If you didn’t get this:
A normal Transformer is like working on a whiteboard with only so much space. Once it’s full, the oldest notes get wiped away and can’t be recovered. Memory-augmented architectures try to fix this by letting the model keep a condensed “sticky note” version of what it saw earlier, so it can still refer back to important details even after they’ve scrolled out of view.
4.1.2 Memory Augmented Models
Area: Architecture; Mechanism: Algorithm; Goals: Reasoning Stability, Truthfulness; Horizon: Mid Term (2-4 years)
While SSMs aim to make processing long sequences more efficient, another class of architectures tackles the memory problem head-on. A core limitation of a standard Transformer is its fixed context window. Once information scrolls past this window, it's forgotten forever. This creates a frustrating "goldfish memory" problem for tasks that require long-term coherence, like managing a multi-day project or acting as a personalized assistant. Memory-Augmented Architectures offer a direct, algorithmic solution by fundamentally changing how a model stores information.
The core idea is to give the model an external, persistent memory bank that acts as a dedicated notebook or scratchpad that it can learn to read from and write to. This separates the model's active computation from its long-term storage. The model learns not only to process language but also to recognize when a piece of information is important enough to "jot down" for later. It can then learn to query this memory to retrieve key facts, user preferences, or past conversation details when they become relevant again.
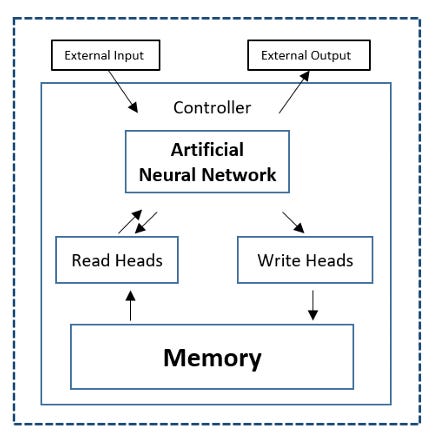
We have an implementation of this today, but it’s an engineering trick not a fundamental architectural shift. A separate system retrieves relevant snippets from your chat history and hands them to the model as temporary context. The model itself doesn't actually remember anything long-term. The true architectural frontier is to build a neuro-integrated memory. This integration make the memory part of the model’s native reasoning loop, whereas ChatGPT’s product-level memory is just a less-rigorous add-on that feeds context back in.
This approach offers a powerful solution for enhancing Reasoning Stability and Truthfulness. For example, a memory-augmented assistant could intrinsically remember a user's long-term goals without needing to be reminded in every session. By grounding its responses in a recorded memory of past interactions, it can provide more accurate, personalized, and contextually aware answers.
While this idea has deep roots in AI research, with foundational papers like DeepMind's "Neural Turing Machines," the current frontier focuses on efficiently integrating these memory systems with today's large-scale foundation models.
If you didn’t get this:
Memory-augmented models fixes Transformer’s short-term memory by giving the model a separate, long-term “notebook” it can write to and read from. This lets it keep important facts and bring them back later, making it much better at holding long, coherent, and personalized conversations.
4.1.3 Neuro-Symbolic Hybrids
Area: Architecture; Mechanism: Algorithm; Goals: Reasoning Stability, Truthfulness, Alignment; Horizon: Long term (5+ years)
While the previous architectures aim to improve the efficiency and memory of neural networks, a third frontier asks a more fundamental question: is the purely neural approach enough? Models like Transformers and SSMs excel at pattern matching and probabilistic reasoning, but they can struggle with tasks that require strict, verifiable logic. They can't truly "show their work" for a complex math problem or guarantee they will follow a hard rule. Neuro-Symbolic Hybrids tackle this problem by fusing two different kinds of intelligence into a single algorithmic system.
The core idea is to combine a neural network with a classical symbolic system — an engine for formal logic, mathematical operations, and structured rules. The neural "artist" handles the fuzzy, intuitive tasks like understanding the nuance of a user's request, while the symbolic "mathematician" takes over for anything that requires precise, step-by-step execution. The model learns to act as a smart project manager, handing off the right part of a problem to the right specialist.
This hybrid approach offers a powerful path to improving Reasoning Stability and Truthfulness. For a logical query, the symbolic engine can execute the steps perfectly and provide a verifiable trace of its work, turning the "black box" of a neural network into a "glass box" where you can check the math. This also enhances Alignment, as it's easier to enforce hard constraints or diagnose reasoning errors when the logic is explicit.
While a longstanding idea, its resurgence in the context of LLMs is still a highly emerging frontier.
4.1.4 Architectural Key Lessons
The architectural frontiers reveal a clear picture of where we’re trying to go. The specific technologies differ, but they point toward a shared future defined by a few key lessons:
The What — Beyond the Monolithic Transformer: Progress is no longer just about building bigger Transformers. The focus has shifted to exploring fundamentally new and diverse designs. There are new architectures like SSMs and there are more modular Transformers, composed of specialized parts for different cognitive functions, like a dedicated logic engine or memory bank.
The Why — A Focus on Reliability over Fluency. The goal is shifting from making models sound more human to making them think more reliably. The frontiers aim to fix core flaws in memory, logic, and efficiency, particularly over large contexts and long task horizons, to build a more trustworthy foundation for AI.
These are the aims, but remember this is the true frontier. These are neither certain in their specific implementations nor their destiny!
3.2 Training: Better Teaching Methods
For years, this training has followed a two-step formula: a long phase of passive, unsupervised learning on a massive snapshot of the internet (pre-training), followed by a shorter alignment phase using expensive, human-generated feedback (post-training). While this approach has produced tremendous results, its limitations are now clear:
the quality of internet data is a bottleneck
relying on human supervisors for alignment doesn't scale
Therefore, the research frontiers in training aim to move beyond this paradigm, creating more active, targeted, and scalable teaching methods that equip models with deeper reasoning and more reliable behavior.
We'll explore three of the most exciting paths: Self-Play & Debate to scale the alignment process, Self-Correction to train models to be effective "doers", not just fluent "talkers", and World Models to teach common sense through simulated experience.
4.2.1 Self-Play & Debate
Area: Training; Mechanism: Algorithm & Data; Goals: Alignment & Incentives; Horizon: Near-Term (1-3 years)
The primary method for aligning models today, Reinforcement Learning from Human Feedback (RLHF), creates a major bottleneck: using humans doesn’t scale because it’s slow and expensive. While using an AI to generate feedback (RLAIF) is a step forward, one way of scaling this is by creating an entire ecosystem of AI agents designed to challenge each other.
The next evolution beyond a simple AI judge in RLAIF is structured Debate and Constitutional Self-Modeling. In this setup:
one model might is prompted to generate an answer
a second, adversarially-prompted model is tasked with finding every possible flaw
a third judge model doesn't just pick a winner, it evaluates the entire debate to model a more nuanced set of preferences
This system moves beyond simple feedback to generating a rich dataset of reasoning, identifying not just what is a better answer, but also why. The goal is to create a system where desirable behaviors like truthfulness and harmlessness are emergent properties of the competitive dynamics. If Model 1 lied, Model 2 would call it out and the judge would penalize model 1 and note the preference to not lie, reinforcing better behavior.
Beyond just scale, this approach has several powerful outcomes:
Novel Flaws: It uncovers "unknown unknowns” by having AIs adversarially attack each other's logic and going deeper, leading to more robust models.
Training for Honesty. It reduces sycophancy by rewarding AI critics for finding objective flaws, not for pleasing a human.
Self-Improving Network. Better models train better critics, which in turn train even better models. This allows the entire system to bootstrap its own intelligence and safety at an accelerating rate.
Of course, there are risks to be managed like AI echo chambers and overfitting on “winning the debate” / gaming the system vs. learning more helpful intelligence. But, if this is carefully managed, we’ll start to have models that improve themselves!
4.2.2 Post-Training via Self-Correction
Area: Training; Mechanism: Algorithm; Goals: Reasoning Stability, Alignment; Horizon: Near-term (1-3 years)
Even if a model can reason well in a debate, that doesn't guarantee it can successfully complete a complex, multi-step task. The real world is messy, and initial plans often fail. This training frontier, Self-Correction, focuses on teaching models to be effective doers, not just fluent talkers. The goal is to create agents that can dynamically adapt their own plans when things don't go as expected, which is a key component of robust Reasoning Stability.
The core idea is to train the model in a feedback loop where it is rewarded for achieving a final goal, not just for following its initial plan. This process teaches the model to observe the outcome of each step it takes. If an action leads to an error or an unexpected result, the model learns to pause, analyze the failure, and generate a revised plan to overcome the obstacle. It internalizes the process of trial and error.
This capability is crucial for improving Alignment with a user's true intent. A model that can self-correct is far more likely to achieve that goal than one that gives up at the first error. This is a core research area for creating capable agentic AI, and it is often trained using a technique called process supervision where the model is rewarded for a sound reasoning process, including the steps where it identifies and corrects its own mistakes.
4.2.3 Learning via World Models
Area: Training; Mechanism: Algorithm & Data; Goals: Reasoning Stability, Truthfulness; Horizon: Mid-Term (2-4 years)
The previous training methods help a model refine its reasoning and actions. But the most effective self-correction happens proactively, before a mistake is even made. This requires a level of common sense that can't be learned from text alone. Text can describe that "dropping a glass might cause it to break," but it doesn't build an intuitive, predictive intuition for physics and causality.
This lack of grounding is a root cause of failures in Reasoning Stability. The goal of World Models is to solve this by allowing the model to learn from direct, simulated experience.
The core idea is to have a model build its own internal, predictive simulation of an environment. Instead of just passively reading, the model actively takes actions within a simulation, observes the outcomes, and updates its internal world model to better predict the consequences, generating a new kind of experiential data. The direct experience of seeing cause and effect over millions of trials builds a much deeper, more robust understanding of how things work.
By building these mental sandbox thoughts (pun intended), the model gains a form of common sense. It can "sanity check" its own plans by running a quick mental simulation before acting, drastically improving its Reasoning and Truthfulness.
This approach was a cornerstone of major breakthroughs in game-playing AI, where agents like DeepMind's AlphaGo built models of their game environments to achieve superhuman performance. The current research frontier is now focused on applying this concept not just to games with fixed rules, but to more open-ended simulations of real-world physics, social dynamics, and human interaction. Successful implementations would truly create intelligence that understands, not just imitates.
To dive more into the topic, Melanie Mitchell has written a great two-part series: Part 1 and Part 2.
4.2.4 Key Notes from Training Frontiers
These training frontiers point to two fundamental shifts in how we teach, both of which are getting models to teach themselves:
Introspective Learning: Instead of relying on fixed, human-curated datasets, these methods turn the AI into a data-generation engine, creating self-critical feedback or using other models to provide that feedback.
Outrospective Learning: Instead of being told how to do things, models are being encouraged to actively learn by doing. Instead of having another party give them feedback, they are having the world give them feedback. The first era has been learning by imitation. The current era is learning by trial and error.
Models that teach themselves and learn by doing is a foundationally different approach to the problem and attacks the problem in a very human way. If we want, them to have intelligence like we do, shouldn’t they learn the same ways too?
4.3 Inference: Smarter Model Application
The frontiers of inference are to build dynamic, adaptive systems that get more value from our trained models at runtime.
We'll explore three key areas: using a Society of Models to pick the right tool for the job, enabling Continual Learning so models can improve from live interactions, and leveraging Hardware-Software Co-design to make the entire process fundamentally cheaper and faster.
4.3.1 Society of Models (Cross-Model Composition)
Area: Inference; Mechanism: Algorithm; Goals: Unit Economics, Reasoning Stability; Horizon: Near-Term (Now-3 years)
A major source of inefficiency in AI today is using a single, massive model for every single task (GPT-5 is changing this). Sending a simple query to a frontier model is like using a supercomputer to do basic arithmetic. The "Society of Models" approach, also known as cross-model composition, tackles this problem by creating a smarter, more efficient algorithmic system for handling user requests.
The idea is to move away from a monolithic system and instead use a lightweight dispatcher / router model to analyze incoming queries and route them to the most appropriate model from a larger collection.
You wouldn't hire one expensive generalist to build a skyscraper; you'd hire a team of specialists.

This works the same way: a simple request might go to a small, fast, and cheap model, while a complex coding problem is routed to a larger, specialized coding model. For multi-step tasks, the dispatcher can create a chain of calls to different specialists, with a final model synthesizing their outputs into a single, coherent answer.
This approach directly attacks two key friction points. It drastically improves Unit Economics by matching the computational cost to the complexity of the task. It also enhances Reasoning Stability by using the best possible "expert" for a given job, leading to higher quality and more reliable outputs.
With GPT-5, we’re at the frontier. We’ll see how it improves and evolves!
4.3.2 Continual Learning
Area: Inference; Mechanism: Algorithm; Goals: Truthfulness, Alignment; Horizon: Mid-Term (2-4 years)
Even a sophisticated "Society of Models" suffers from a fundamental limitation: the models themselves are static. A model trained in August 2025 is permanently frozen with the knowledge of that date, quickly becoming stale and unable to learn from its interactions. This is a major barrier to long-term Truthfulness and deep personalization. Continual Learning is a "holy grail" research frontier that aims to solve this by enabling models to learn and evolve after they've been deployed.
The challenge is to allow a model to integrate new information from live user interactions without needing to be completely retrained from scratch. This is incredibly difficult due to a problem known as catastrophic forgetting, where a neural network learning new information tends to overwrite and destroy its previous knowledge.

Successfully cracking this problem would be transformative. A model that could learn from corrections would become more accurate and truthful over time. It would also unlock a new level of Alignment through deep personalization as the model could learn your specific preferences, work style, and context, becoming a truly adaptive partner.
While perfect continual learning is a long-term goal, the research into overcoming catastrophic forgetting is a major focus, with practical methods for enabling specific kinds of model updates emerging in the mid-term.
4.3.3 Hardware-Software Co-Design
Area: Inference; Mechanism: Compute & Algorithm; Goals: Unit Economics; Horizon: Near-Term (Ongoing)
All of the algorithmic and system-level innovations we've discussed rely on one thing: raw computational power. The cost, speed, and energy required to run these massive models is a fundamental barrier to widespread adoption and a core Unit Economics problem. The final frontier of inference addresses this at the most foundational layer: the physical silicon itself. Hardware-Software Co-design is a synergistic approach where the AI models (software) and the chips they run on (hardware) are developed in tandem.
Instead of running models on general-purpose GPUs, companies are building custom AI accelerator chips (ASICs) designed to perform neural network math, like matrix multiplications, really efficiently. The model's algorithm can even be tweaked to favor operations that its custom compute hardware is exceptionally good at, creating a powerful feedback loop.
4.3.4 Inference Frontier Takeaways
The frontiers of inference show a clear trend: moving away from a simple request-response loop with a single model and toward building sophisticated, efficient, and "live" AI systems:
A Model to a Full System: The focus is shifting from treating a single model as the product to building an intelligent system, using routers, specialized models, and dynamic workflows.
Unit Economics Dictates Everything: As AI becomes a utility, the cost and speed of inference are paramount. Much of the most critical research, from smart orchestration down to custom chip design, is driven by a relentless focus on making AI radically cheaper and faster at the point of use.
The "Static Model" is Becoming Obsolete: The strict line between a "training phase" and a "deployment phase" is beginning to blur. Models are becoming living entities that can learn and adapt at increasing periodicities.
4.4 Takeaways at the Frontier
Across all research areas, a few fundamental shifts in thinking define the frontier:
From Monolithic Models to Intelligent Systems: The frontier is "unbundling" the all-knowing LLM into a system of specialized components. Architectures are becoming modular (with dedicated memory or logic) and inference is run by a "Society of Models" that routes tasks to the right expert. This is because the system is the product, not the individual model.
Models Improve Themselves, Not Just Researchers: With frontiers like Continual Learning, Self-Correction, and world-models, models are becoming models that teach and improve themselves. No longer are they bound to the prescriptive influence of the researchers in charge, but instead they are cast out into the world and asked to learn on its own.
From Brute Force to Frugal Intelligence: Instead of applying maximum compute to every problem, the smartest systems are becoming the most frugal. They use efficient architectures (SSMs, MoE) and adaptive inference, only activating expensive reasoning for difficult tasks. It’s about knowing when not to use your full power, making advanced AI economically viable. Unit economics are everything!
These shifts are the some of the foundational changes that will determine whether we transform AI from a novel technology into a generationally ubiquitous and trustworthy utility.
5. The Great Debate: What Happens Next
In the last section, we explored the most promising research frontiers — from radically efficient architectures like SSMs, to smarter training methods like world models, to inference systems that can learn on the fly. Each of these innovations is aimed squarely at today’s friction points, with the potential to make AI more reliable, efficient, and capable.
But these projects are part of a much bigger, high-stakes debate over the future of AI between two forces:
Scaling: pushing today’s foundations further with more data, more compute, and more optimization.
Breakthroughs: finding the next paradigm that changes the rules entirely.
This final section zooms out from the individual lab experiments to analyze this ultimate race. Do we just need to feed current foundations more data and compute? Or must we discover a fundamentally new way of building intelligence to reach the next level? The outcome of this race and its timing will determine the trajectory of AI for years to come.
To understand this debate, we will:
Understand the two competing paths in this race.
Analyze the core tension that makes timing everything
Outline what you need to believe to pick a side
Let’s dive in one last time!
5.1 The Big-Picture: How Do We Make Progress?
Every improvement to our value per dollar-second yardstick comes from pulling one of two strings:
Scaling: Stretching the current paradigm to its limits.
Breakthroughs: Finding a new paradigm that resets the game.
Both can raise capability, improve reliability, and reduce cost/latency, but they do it in very different ways.
Scaling
This is the path of predictable, incremental gains. We take today’s best-known architectures (currently Transformer-based LLMs) and push them further with more training data and more compute.
For a while, scaling tends to improve both value and decrease dollar-second by making inference faster and cheaper relative to the capability delivered. However, scaling requires ever-increasing resources and eventually hits a point of scaling saturation, where the cost and data required to achieve the next increment of value become prohibitively high and returns diminish for the paradigm.
Breakthroughs
This is the path of non-linear innovation leaps that change the slope of the curve entirely. A breakthrough can come from a new architecture, training method, or system design that unlocks capabilities scaling alone couldn’t reach. They restart the progress curve, offering a new foundation for growth just as the old one becomes unsustainable.
The Critical Tension
The challenge is timing. If scaling can carry us far enough before saturation, we buy more time for breakthroughs to emerge. But if scaling flattens out before the next breakthrough arrives, progress stalls and the industry shifts to wringing more efficiency and creativity out of the fixed capability set.
5.2 The Great Debate: Scaling or Breakthrough?
The critical tension between scaling and breakthroughs isn't just a theoretical dilemma. It's the central, high-stakes contest defining AI research today. Both sides agree on the goal: keep pushing our value per dollar-second yardstick upward, but they differ in their confidence in how much each path may yield.
5.3.1 The Scaling Camp
This camp believes the current paradigm still has a long runway. They are focused on extending the life of the Transformer architecture by overcoming the primary bottlenecks of data and compute. Their efforts are focused on:
Data Scaling: Solving the looming data scarcity problem through methods like the synthetic data flywheel, where models generate high-quality data to train their successors (while avoiding the “echo chamber” trap of compounding low-quality generations).
Compute Scaling: Relying on compute spend and data center CapEx to keep the cost curve for compute dropping faster than demand is rising, making ever-larger models economically viable.
In this view, we don’t need to abandon Transformers yet, we just need to keep feeding them.
5.3.2 The Breakthrough Camp
This camp is betting against the viability of the scaling approach, arguing that Transformers have fundamental limitations that more data and compute can't fix. They are actively working on new model designs and algorithms like SSMs, MAGs, and Neuro-Symbolic hybrids to unlock capabilities scaling cannot.
These approaches aim to restart the curve by delivering capabilities scaling can’t reach, while also cutting dollar-second in ways scaling struggles to match.
5.3.3 The Messy Middle
In practice, both camps are working in parallel. Scaling teams are also exploring breakthrough ideas, and breakthrough-focused teams still rely on scaling to prove their concepts.
But the real strategic divide comes down to timing: Will scaling give us enough runway for the next breakthrough to arrive, or will the curve flatten before the new foundation is ready?
5.3 Picking a Side: What You Need to Believe
For sustained, exponential progress on our value per dollar-second yardstick to continue, you must hold one or both of the following beliefs:
We Have More Scaling Runway: Scaling data and compute will not hit a prohibitive wall in the near term. Synthetic data flywheel will work without creating echo chambers and hardware / software innovations will continue to make massive compute clusters economically viable. Progress still has significant room to grow before it begins to flatten, so we are not yet near the point of saturation.
A Breakthrough Will Arrive in Time: Regardless of the length of the scaling runway, a meaningful architectural or algorithmic innovation will emerge before or soon after the current runway runs out. This new paradigm would restart the cycle, kicking off a new S-curve of exponential growth before the industry experiences a major and extended slowdown.
If both beliefs are right, the outcome is the best-case curve: scaling extends the current trajectory while a breakthrough lands just in time to accelerate it further. If only one is right, we still see progress, but the pace and magnitude depend on which lever delivers and to what extent.
If neither is right, scaling hits a wall and no breakthrough is ready leading model capability to plateau. The industry’s focus shifts downstream: optimizing inference costs, building clever application-layer systems, and extracting new value from fixed foundational capabilities.
The stakes are high. It’s whether AI’s next chapter is written as a smooth acceleration, a jagged leap, or a frustrating stall.
6. Primer Recap
In Part 1 we calibrated our instruments, learning the core principles of prediction and error on a simple problem to learn the basics. In Part 2, we used those principles to chart the vast and intricate territory of the Transformer, mapping its architecture from the first token to the final prediction. Our expedition continued in Part 3 as we explored the infrastructure built upon that territory: the capabilities that transformed a core engine into a dynamic, multimodal agent with "hands, eyes, and ears."
Finally, in Part 4, we climbed to a strategic vantage point. From here, we surveyed the current friction points, the frontiers of research, and the great debate between scaling and breakthroughs that will define the routes into uncharted lands.
This map is more than just a technical diagram: it is a new lens for understanding the technology that is actively reshaping our world. With this complete picture, you are now equipped to move beyond the headlines and form the thoughtful perspectives we set out to build.
When you hear about the challenge of "AI alignment," you will understand the mechanics of RLHF and the promising frontiers of self-play and debate. When a new model boasts a "million-token context window," you will recognize the architectural innovations like RoPE, FlashAttention, and maybe even State-Space Models that make it possible. When you read about the race toward more capable AI, you will see it not as esoteric magic, but through the clear-eyed framework of data, algorithms, and compute.
The AI landscape will continue to change at a breathtaking pace. Today's frontier is tomorrow's foundation but the principles you have learned here will endure.
The journey of understanding doesn't end here; it begins. You now have the primer to navigate what comes next.
Go to the main page.
7. Appendix
7.1 Glossary
Breakthroughs: The process of achieving progress through non-linear, innovative leaps that introduce a new paradigm, such as a novel architecture or training method, changing the fundamental rules of how AI is built.
Continual Learning: A research frontier aimed at enabling models to learn and evolve from new data and live user interactions after they have been deployed, without needing to be completely retrained. The primary challenge is overcoming "catastrophic forgetting," where learning new information overwrites previous knowledge.
Hardware-Software Co-design: A synergistic approach where AI models (software) and the custom accelerator chips they run on (hardware) are developed in tandem. This creates a powerful feedback loop, optimizing both the algorithms and the silicon for maximum efficiency.
Memory-Augmented Architectures: Models designed with an external, persistent memory bank that they can learn to read from and write to. This allows them to overcome the fixed context window limitations of standard Transformers and maintain long-term coherence.
Neuro-Symbolic Hybrids: A type of model architecture that combines a neural network (for pattern matching and intuitive tasks) with a classical symbolic system (for formal logic and structured rules). This fusion aims to improve reasoning stability and truthfulness by handling different parts of a problem with the appropriate specialized engine.
Scaling: The strategy of improving AI capabilities by pushing the current paradigm (e.g., Transformers) further with more data, more compute, and larger model architectures.
Scaling saturation: The point at which the cost and resources required to achieve the next small increment of improvement from scaling a particular paradigm become prohibitively high, leading to diminishing returns.
Self-Correction: A training method focused on teaching a model to be an effective "doer" by learning to dynamically adapt its plans when it encounters errors. The model is rewarded for achieving a final goal, which encourages it to learn from trial and error and revise its own steps.
Self-Play & Debate: A training technique where multiple AI agents are set up to challenge and critique each other's outputs. For example, one model generates an answer, another finds flaws, and a third judges the exchange. This process scales the creation of alignment data and helps uncover novel model failures.
Society of Models (Cross-Model Composition): An inference strategy that uses a lightweight "dispatcher" or "router" model to analyze incoming queries and route them to the most appropriate, specialized model from a collection. This improves efficiency by matching the computational cost to the complexity of the task.
State-Space Models (SSMs): An architectural design for processing sequences that reads information linearly, one piece at a time, while maintaining a compressed summary or "state" of what it has seen. This approach avoids the quadratic scaling issues of Transformers, making it more efficient for long sequences.
World Models: A training approach where a model builds its own internal, predictive simulation of an environment (a "world model"). By taking actions in this simulation and observing the outcomes, the model learns common sense, causality, and how the world works through direct, simulated experience rather than just from static text.